3. La Transcription "Augmentée" (Centre - Lecture Sélective) > solution technique proposition
C'est une excellente question qui touche au cœur de l'architecture "Backend for Frontend". Pour réaliser cette interface fluide, vous ne pouvez pas simplement demander à l'IA de "résumer". Il faut orchestrer plusieurs appels API spécifiques pour structurer la donnée avant de l'envoyer au frontend.
Voici l'architecture technique pour réaliser ces 3 fonctionnalités avec OpenAI (GPT-4o / Embeddings) ou Google Gemini (1.5 Flash/Pro).
1. Chapitrage Automatique (Segmentation)
Le défi : Transformer un flux continu de texte en blocs logiques avec des timestamps. La solution technique : Le "Prompting Structuré" (JSON Mode).
Au lieu de demander du texte, vous forcez l'API à vous répondre en JSON.
- Input : La transcription complète (avec timestamps).
- Prompt (Instruction) : "Agis comme un analyste commercial. Découpe cette transcription en chapitres logiques (Intro, Découverte, Pitch, etc.). Pour chaque chapitre, donne-moi un titre H2 court, un résumé en une phrase, et le timestamp de début et de fin."
- Technologie :
- OpenAI : Utilisez la fonctionnalité Structured Outputs (avec un schéma Pydantic ou JSON Schema) pour garantir que le format est respecté à 100%.
- Google Gemini : Utilisez response_schema avec Gemini 1.5 Flash (très rapide et peu coûteux pour ce volume de texte).
Exemple de sortie JSON (prête pour le Front) :
JSON
{
"chapters": [
{
"title": "Introduction et prise de contact",
"start_time": "00:00",
"end_time": "02:15",
"summary": "Présentations et validation de l'agenda."
},
{
"title": "Découverte des besoins",
"start_time": "02:16",
"end_time": "08:45",
"summary": "Le client exprime des soucis avec son CRM actuel."
}
]
}
2. Surbrillance Intelligente (Extraction d'Entités)
Le défi : Repérer des concepts ("Moment Prix") et non juste des mots ("500€"). La solution technique : Extraction d'Entités Nommées (NER) via LLM.
Vous ne faites pas un "CTRL+F". Vous demandez à l'IA d'identifier les passages correspondant à vos définitions de "Moments".
- Input : Transcription + Votre liste de définitions (ex: Moment Prix = "Toute mention de coût, budget, ou trop cher").
- Prompt : "Identifie tous les segments de texte correspondant aux définitions suivantes. Retourne la citation exacte et la catégorie."
- Technologie : GPT-4o-mini ou Gemini 1.5 Flash sont parfaits ici.
Astuce UX : Le backend renvoie les "offsets" (position du caractère de début et de fin) pour que votre frontend puisse appliquer la balise <mark class="yellow"> au bon endroit.
3. Recherche Sémantique ("Budget" trouve "C'est cher")
Le défi : Comprendre le sens, pas les lettres. La solution technique : Les Embeddings (Vecteurs). C'est la partie la plus technique mais la plus puissante.
L'IA ne lit pas, elle calcule des distances mathématiques entre les concepts.
- Indexation (Au moment de l'enregistrement de l'appel) :
- Vous découpez la transcription en petits morceaux (chunks) de 3-4 phrases.
- Vous passez chaque morceau dans une API d'Embedding (OpenAI text-embedding-3-small ou Google text-embedding-gecko).
- L'API vous rend une liste de chiffres (un vecteur) pour chaque phrase. Vous stockez cela dans une base de données vectorielle (Pinecone, Milvus, ou même PostgreSQL avec pgvector).
- Recherche (Quand l'utilisateur tape "Budget") :
- L'utilisateur tape "Budget".
- Vous envoyez le mot "Budget" à la même API d'Embedding. Elle le transforme en vecteur.
- Vous demandez à votre base de données : "Quels morceaux de la conversation ont un vecteur mathématiquement proche de celui de 'Budget' ?"
- La base va ressortir "C'est un peu cher pour nous" car, vectoriellement, ces concepts sont voisins.
Résumé de la Stack Technique Recommandée
Résumé de la Stack Technique Recommandée
| Fonctionnalité | Outil Recommandé (OpenAI) | Outil Recommandé (Google) | Pourquoi ? |
| Chapitrage | GPT-4o-mini (avec Structured Outputs) | Gemini 1.5 Flash | Le "mini/flash" suffit largement pour structurer et coûte 10x moins cher. |
| Surbrillance | GPT-4o | Gemini 1.5 Pro | Nécessite un peu plus de "nuance" pour bien comprendre le contexte subtil (ex: ironie). |
| Recherche | text-embedding-3-small | Gecko (Vertex AI) | Rapide, léger, et permet la recherche par concept. |
"Techniquement, nous n'avons pas besoin de réinventer la roue. Le chapitrage utilise des LLM standards (commodity), mais la recherche sémantique nécessitera de mettre en place une petite base vectorielle.
C'est un investissement d'architecture minime pour un effet 'Wow' maximal chez le client."
.
Peux tu me faire le code d'un coté de l'UX en REACT JS et les call API .?
C'est parti. Pour que ce soit concret et utilisable pour une démo (PoC), je vais diviser cela en deux parties :
- Le Frontend (React) : Qui se concentre sur l'affichage intelligent (Chapitres + Texte surligné).
- Le Backend (Node.js/Express simu) : Qui montre comment appeler OpenAI pour structurer la donnée.
1. Le Frontend (React JS
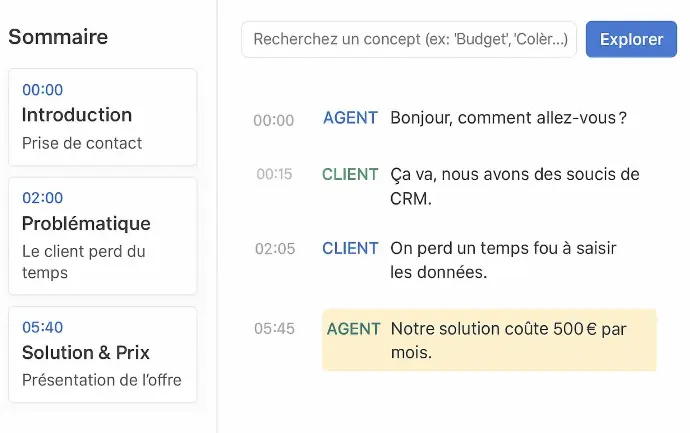
1. Le Frontend (React JS)
Ci-contre une représentation image du code REACT JS de ci-dessous
1. Le Frontend (React JS)
L'objectif est de créer une interface avec une Sidebar de chapitres et une Zone de lecture qui réagit à la recherche sémantique.
J'utilise une approche modulaire.
JavaScript
import React, { useState, useEffect, useRef } from 'react';
// --- TYPE DE DONNÉES ATTENDU DU BACKEND ---
// C'est le contrat d'interface. Le backend doit renvoyer ça.
const MOCK_DATA = {
chapters: [
{ id: 1, title: "Introduction", startTime: 0, summary: "Prise de contact" },
{ id: 2, title: "Problématique", startTime: 120, summary: "Le client perd du temps" },
{ id: 3, title: "Solution & Prix", startTime: 340, summary: "Présentation de l'offre" }
],
transcriptSegments: [
{ id: 'seg1', time: 0, speaker: 'Agent', text: "Bonjour, comment allez-vous ?" },
{ id: 'seg2', time: 15, speaker: 'Client', text: "Ça va, nous avons des soucis de CRM." },
{ id: 'seg3', time: 125, speaker: 'Client', text: "On perd un temps fou à saisir les données." },
{ id: 'seg4', time: 345, speaker: 'Agent', text: "Notre solution coûte 500€ par mois." }
]
};
const SmartTranscript = () => {
const [data, setData] = useState(MOCK_DATA);
const [searchQuery, setSearchQuery] = useState('');
const [highlightedSegmentIds, setHighlightedSegmentIds] = useState([]);
const textContainerRef = useRef(null);
// --- FONCTION : RECHERCHE SÉMANTIQUE (Appel API) ---
const handleSearch = async () => {
if (!searchQuery) return;
// Simulation d'un appel API vers votre Backend (voir section 2)
// const response = await fetch('/api/semantic-search', { method: 'POST', body: { query: searchQuery } });
// const results = await response.json(); // Retourne des IDs de segments
// MOCK pour la démo : Si on tape "Budget", on surligne le segment qui parle de prix
if (searchQuery.toLowerCase().includes('budget')) {
setHighlightedSegmentIds(['seg4']); // Le segment qui dit "500€"
scrollToSegment('seg4');
}
};
// --- UX : SCROLL AUTOMATIQUE ---
const scrollToSegment = (id) => {
const element = document.getElementById(id);
if (element) {
element.scrollIntoView({ behavior: 'smooth', block: 'center' });
element.classList.add('flash-highlight'); // Animation CSS temporaire
}
};
return (
<div className="flex h-screen bg-gray-50 font-sans">
{/* --- SIDEBAR : CHAPITRAGE --- */}
<div className="w-1/4 bg-white border-r border-gray-200 p-4 overflow-y-auto">
<h2 className="text-xl font-bold mb-4 text-gray-800">Sommaire</h2>
<div className="space-y-3">
{data.chapters.map((chapter) => (
<div
key={chapter.id}
className="p-3 rounded-lg hover:bg-blue-50 cursor-pointer border border-gray-100 transition"
onClick={() => alert(`Saut vers ${chapter.startTime}s (Player Audio)`)}
>
<div className="text-xs text-blue-500 font-bold uppercase">{formatTime(chapter.startTime)}</div>
<h3 className="font-semibold text-gray-700">{chapter.title}</h3>
<p className="text-sm text-gray-500 mt-1">{chapter.summary}</p>
</div>
))}
</div>
</div>
{/* --- MAIN : TRANSCRIPTION AUGMENTÉE --- */}
<div className="w-3/4 flex flex-col">
{/* BARRE DE RECHERCHE SÉMANTIQUE */}
<div className="p-4 border-b bg-white shadow-sm flex gap-2">
<input
type="text"
placeholder="Recherchez un concept (ex: 'Budget', 'Colère')..."
className="flex-1 p-2 border rounded-md focus:ring-2 focus:ring-blue-500 outline-none"
value={searchQuery}
onChange={(e) => setSearchQuery(e.target.value)}
onKeyDown={(e) => e.key === 'Enter' && handleSearch()}
/>
<button
onClick={handleSearch}
className="bg-blue-600 text-white px-4 py-2 rounded-md hover:bg-blue-700"
>
Explorer
</button>
</div>
{/* ZONE DE LECTURE */}
<div className="flex-1 overflow-y-auto p-8" ref={textContainerRef}>
{data.transcriptSegments.map((seg) => (
<div
key={seg.id}
id={seg.id}
className={`mb-4 flex ${highlightedSegmentIds.includes(seg.id) ? 'bg-yellow-100 -mx-2 p-2 rounded' : ''}`}
>
<div className="w-16 text-xs text-gray-400 font-mono mt-1">
{formatTime(seg.time)}
</div>
<div className="flex-1">
<span className={`text-xs font-bold uppercase mr-2 ${seg.speaker === 'Agent' ? 'text-blue-600' : 'text-green-600'}`}>
{seg.speaker}
</span>
<p className="text-gray-800 leading-relaxed inline">
{/* Surlignage intelligent (Highlight) */}
{highlightedSegmentIds.includes(seg.id) ? (
<mark className="bg-yellow-200 text-gray-900">{seg.text}</mark>
) : (
seg.text
)}
</p>
</div>
</div>
))}
</div>
</div>
</div>
);
};
// Petit helper pour le temps (0 -> 00:00)
const formatTime = (seconds) => {
const m = Math.floor(seconds / 60);
const s = seconds % 60;
return `${m}:${s < 10 ? '0' : ''}${s}`;
};
export default SmartTranscript;
2. Le Backend (Node.js + OpenAI API)
Voici la logique des deux routes API critiques pour alimenter le React ci-dessus.
A. Route /process-audio : Le Chapitrage Automatique
Cette route prend le texte brut et renvoie le JSON structuré (Chapitres).
JavaScript
import OpenAI from "openai";
const openai = new OpenAI();
app.post('/api/process-audio', async (req, res) => {
const { fullTranscriptText } = req.body;
// 1. Définition du schéma de sortie (JSON Mode Strict)
const chapterSchema = {
type: "json_schema",
json_schema: {
name: "transcription_analysis",
schema: {
type: "object",
properties: {
chapters: {
type: "array",
items: {
type: "object",
properties: {
title: { type: "string" },
summary: { type: "string" },
start_time_seconds: { type: "number" }
},
required: ["title", "summary", "start_time_seconds"]
}
}
},
required: ["chapters"]
}
}
};
// 2. Appel à GPT-4o-mini (Rapide et pas cher)
const completion = await openai.chat.completions.create({
model: "gpt-4o-mini",
messages: [
{ role: "system", content: "Tu es un assistant expert en analyse d'appels commerciaux." },
{ role: "user", content: `Analyse cette transcription et découpe-la en chapitres logiques : ${fullTranscriptText}` }
],
response_format: chapterSchema,
});
// 3. Renvoi du JSON propre au Front
const structuredData = JSON.parse(completion.choices[0].message.content);
res.json(structuredData);
});
B. Route /semantic-search : La Recherche par Concept
C'est ici que la magie opère. Le client tape "Budget", on trouve le segment "500€".
Note : Pour que cela fonctionne, vous devez avoir préalablement vectorisé vos segments (Chunking + Embedding) dans une base de données (ex: Pinecone ou un simple vecteur en mémoire pour le test).
JavaScript
app.post('/api/semantic-search', async (req, res) => {
const { query } = req.body; // ex: "Le client trouve ça trop cher"
// 1. Transformer la requête utilisateur en vecteur (Embedding)
const embeddingResponse = await openai.embeddings.create({
model: "text-embedding-3-small",
input: query,
});
const queryVector = embeddingResponse.data[0].embedding;
// 2. Recherche vectorielle (Pseudo-code base de données)
// On compare ce vecteur avec ceux de nos segments de transcription stockés en DB
// "findNearestNeighbors" est une fonction fictive de votre DB Vectorielle
const nearestSegments = await database.findNearestNeighbors({
vector: queryVector,
limit: 3, // On veut les 3 segments les plus pertinents
minScore: 0.7 // Seuil de similarité
});
// 3. Renvoyer les IDs des segments au Front
// Le React va recevoir ['seg4', 'seg12'] et les mettre en jaune
res.json({ segmentIds: nearestSegments.map(s => s.id) });
});
L'API de Chapitrage utilise le response_format: json_schema. C'est la garantie que l'IA ne va pas "bavarder" mais agir comme une fonction code qui retourne des données structurées fiables pour l'UI.
La recherche n'est pas un CTRL+F. On transforme la question en mathématiques (vecteur), et on cherche les paragraphes mathématiquement proches. C'est ce qui permet de trouver "Prix" quand on tape "Budget".